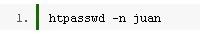默认情况下,当我们访问网站的某个无索引文件(如index.html,index.htm或index.php)目录时,服务器会显示该目录的文件和子目录列表,这是非常危险的,因为它可能暴露网站的内部结构,也许不小心就将含有敏感信息的文件公之于众了,为了禁止这种行为,我们可以在网站根目录创建一个.htaccess文件,内容如下:
当我们从服务器请求一个找不到的文件时,默认情况下服务器会返回404状态码,浏览器和访问者便知道URL指定的位置找不到该文件,但这是一个通用的消息,没有太大的实际意义,我们希望告诉浏览器和访问者更多有用的信息,如:
◆文件被永久移走
状态码301告诉浏览器文件已经被永久移动到另一个位置,这样我们就可以通过.htaccess文件实现重定向了,例如,使用下面的代码可以将浏览器重定向到新的地址:
Redirect 301 /path/from/htaccess/file.html http://www.domain.tld/path/file.html
◆文件被暂时移走
状态码307告诉浏览器文件已经被移走,但这是暂时的,浏览器接收到301状态码时就会访问新地址,但不用改变文件的链接,也不会为新地址创建缓存(除非它受Cache-Control或过期头信息字段控制),浏览器每次都会继续请求源地址。
Redirect 307 /path/from/htaccess/file.html http://www.domain.tld/path/file.html
◆文件不存在
状态码410告诉浏览器,它请求的文件已经从服务器上永久删除,和404不一样,404仅仅表示文件不在这里的意思,而410表示文件不仅不在这里,在其它地方也没有。
如果不向浏览器返回状态码,我们可以创建自己的错误页面,我们可以创建一个自定义错误页面,例如,对于401状态码我们可以创建一个未经授权的错误页面,对于404状态码,我们可以创建一个未找到错误页面,我们需要做的就是修改.htaccess文件,添加下面两行代码:
这个设置告诉浏览器保持文件的缓存多长时间,在未过期前,访问该文件时就不用向服务器发起请求了,服务器向浏览器返回文件时,会附加上一个Expires头信息。
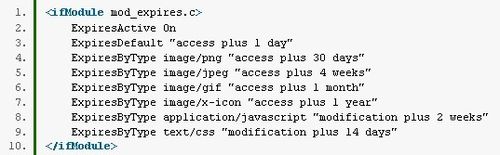
我们可以使用ExpiresDefault指令后面跟一个基础时间+时间长度设置文件的默认过期时间,使用ExpiresByType指令后面跟一个文件类型+基础时间+时间长度指定特定文件类型的过期时间。
基础时间可以是访问时间,它从浏览器请求该文件时开始计数,也可以是修改时间,它从文件最后一次修改时间开始计数,注意,如果你使用修改时间,返回给浏览器的动态内容不会加上Expires头,如动态生成的图像,因为非已存在的文件不存在修改时间。
过期时间要和基础时间结合使用,通过添加一个plus和一个时间,这个时间可以给出年、月、日,时、分、秒,如果我们只使用一个单位,可以使用单数表示,例如,我们可以指定它为“1分钟”或“10分钟”。
在下面的例子中,我使用ExpiresDefault指令将所有文件的默认过期时间设为1天,然后使用ExpiresByType指令为不同文件类型指定过期时间。
任何现代浏览器都能处理服务器压缩过的文件,这样做也是为了减少页面的载入时间,如果服务器默认没有开启文件压缩功能,我们可以通过.htaccess文件来开启。
AddOutputFilterByType DEFLATE text/html text/plain text/xml text/css application/javascript application/x-javascript application/rss+xml application/atom_xml text/javascript
注意,我这里没有为图像文件开启压缩,因为我们的图像文件已经通过其它压缩技术处理好了。
为了保护含有敏感数据的特殊文件夹,我们需要创建一个包含有效的用户名和密码的文件,然后在.htaccess文件中添加一些设置,但用户名和密码仍然是以明文形式发送到服务器的,因此很容易受到中间人攻击,除非我们使用SSL。
首先,我们创建一个名为.htpasswd的文件,将权限修改为600(只有文件所有者有读写权),这样其他用户才不能访问。创建好文件后,我们需要向这个文件注入用户名和密码,如果你使用Linux或Unix类操作系统,使用htpasswd命令就可以办到,如果你能通过SSH登陆到你的服务器,那么你可以使用htpasswd管理.htpasswd文件中的用户名和密码,如果不行,还有很多在线工具可以帮助你生成.htpasswd文件中使用的密码。
使用下面的命令可以向这个文件中注入用户名和密码:如:它会提示你输入密码,然后他会加密密码并保存到.htpasswd文件中。如果Apache是安装在除Windows,Netware和TPF(一种IBM大型机)外的任何系统上,默认情况下下,它会调用crypt()函数加密密码。使用这个命令我们可以创建多个用户,并可以修改已有用户的密码,你可以使用-n参数获得加密后的密码字符串值。它会返回类似下面这样的字符串:然后用文本编辑器打开.htpasswd文件,将上面返回的内容粘贴到文件中,每行代表一个用户。
还可以使用-m参数调用md5加密方法加密密码,在Windows,Netware和TPF下,默认就使用的是md5加密,也可以适应-s参数调用SHA加密,使用-d参数告诉命令调用crypt函数,在大多数系统上,这也是默认的行为。
如果文件不存在,则添加-c参数,它会创建文件,如果文件已经存在,添加这个参数后就会重写整个文件,只留下新创建的用户,如果想删除.htpasswd文件中的某个用户,使用-D参数。
最后,我们可以和其它命令结合使用,如果加入参数-b,我们可以直接在命令中加上密码,但这样做是不安全的。
htpasswd .htpasswd juan randompassword
创建好用户后,他们就可以访问这个目录及其子目录了,但我们还需要在要保护的文件夹下添加一个.htaccess文件,内容如下:
这里的AuthName指的是要求你输入用户名和密码时的提示信息,AuthType表示需要的认证类型,在这个例子中,我只想弹出一个对话框,要求输入用户名和密码,因此设置为Basic,AuthUserFile指的是保存用户名和密码的文件位置,在这个例子中指的是.htpasswd文件,位置和我们的.htaccess文件相同,Require valid-user指定只有.htpasswd文件包含的合法用户才能访问。
为了将html扩展名文件当作php文件使用,需要在.htaccess文件中添加下面的内容:这样服务器就会把HTML文件作为PHP文件进行解析。
如果我们不能访问php.ini文件,有些主机服务商允许我们修改.htaccess文件来改变一些PHP设置,例如,我想生成所上传图片的缩略图,有些主机服务商默认将PHP的内存限制为2MB,显然要生成缩略图是不够用的,因此我要将这个限制改大一点,如增加到16MB,如果要移除内存限制,可以将其设为-1。
为了在.htaccess文件中修改PHP设置,服务器必须启用了AllowOverride Options(或AllowOverride all)选项,如果那样,我们只需要在.htaccess文件中添加下面一行命令即可: